Spontaneous Visual Routines
What actually is a "Visual Routine"?
Visual processing usually seems both incidental and instantaneous. (You see color, for example, without needing to try, and without any noticeable lag.) There are, however, fascinating exceptions to this rule. For example, take a moment to glance at this picture before moving on.
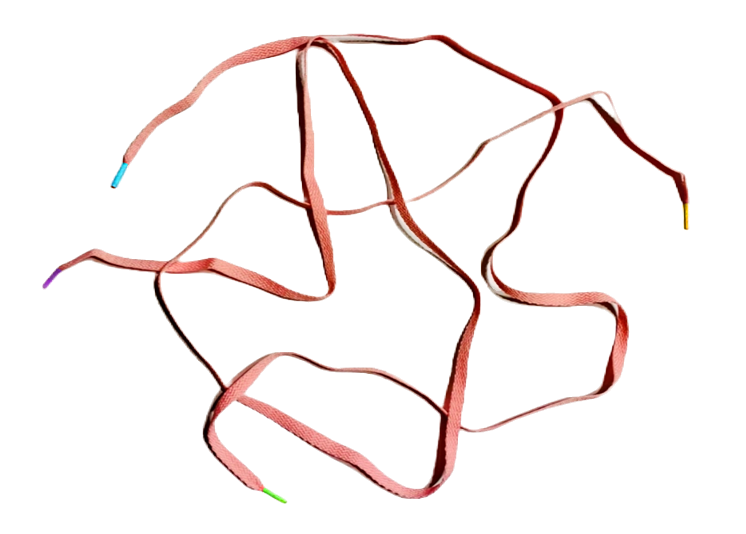
Now consider some questions that could be asked about that picture (without looking back at it!)
(1) What colors were in the picture?
You can probably answer that question immediately, from memory — indicating that this property was extracted even before you were asked the question, just as a part of natural viewing.
But what about this question:
(2) Were the green tip and the blue tip part of the same shoelace, or two different shoelaces?
You probably don’t know the answer yet, which indicates that this property was not extracted incidentally during natural viewing. When you look back at the shoelace picture, of course, you can answer this question too — and you can do so merely by looking (i.e. even without using your finger to follow along a lace). But notice that even here you can’t answer the question immediately: whereas you see the laces’ color seemingly instantaneously, seeing which tip goes with which seems to involve a process that is appreciably deliberate, dynamic, and temporally extended (as you mentally ‘trace’ from one tip to another).
These types of visual operations that underlies your ability to answer the which-tip-goes-with-which question has been termed ‘visual routines’ (Ullman, 1984, 1996), and visual routines contrast with other forms of perception precisely in terms of the two features highlighted in that example: they are often invoked only on demand (rather than always occurring automatically), and they are inherently, appreciably dynamic, such that these operations often take some appreciable time to be executed.
Not only has there been discussion of how visual routines may lie at the root of well-known visual processes such as: figure-ground relationships, containment (e.g. “Is it inside?”), and connectedness (e.g. “Are both points on the same contour?”), but they have been prominent enough to be reviewed in introductory textbooks (e.g. Palmer, 1999).
The Current Project
The work here studies visual routines under a new lens, re-examining the assumptions that traditionally defined visual routines, and exploring new contexts where visual routines may operate. (Spoiler: mazes!)

Wong, K. W., & Scholl, B. J. (2024). Spontaneous path tracing in task-irrelevant mazes: Spatial affordances trigger dynamic visual routines.
Journal of Experimental Psychology: General. 153(9), 2230-2238.
[DOI] [PDF]
Wong, K. W., & Scholl, B. J. (2023). What memories are formed by dynamic 'visual routines'? Poster presented at the annual meeting of the Vision Sciences Society, 5/22/23, St. Pete Beach, FL.
[Show abstract]
You can readily see at a glance how two objects spatially relate to each other. But seeing how 20 objects all relate seems impossible, due to computational explosion (with 190 pairs). Such situations require visual routines: dynamic visual procedures that efficiently compute various properties 'on demand' -- e.g. whether two points lie on the same winding path, in a busy scene containing many points and paths ('path tracing'). Some surprisingly foundational questions about visual routines remain unexplored, including: what (if anything) remains in visual memory after the execution of a visual routine? Does path tracing result in a memory of the traced path itself? Or just of whether there was a path? Or nothing at all, after the moment has passed? We explored this for spontaneous path tracing in 2D mazes. Observers saw a maze in which two probes appeared in positions connected by a path. They were then shown two mazes, and had to select which was the initially presented maze. Across experiments, the incorrect maze could be (1) a Path-Obstruction maze, where a new contour blocked the initial inter-probe path; (2) an Irrelevant-Obstruction maze, where a new contour was introduced elsewhere; or (3) an Alternative-Path maze, where the same new Path-Obstruction contour was accompanied by the removal of an existing contour, providing an alternative inter-probe path. Performance on Path-Obstruction trials was much better than on Irrelevant-Obstruction trials (always controlling for lower-level contour properties across trial types). But Alternative-Path trials entirely eliminated this advantage. This suggests that a visual memory is formed by spontaneous path tracing, but that its content is not the path itself, but only whether a path existed. If visual routines exist to answer on-demand questions during perception, then the resulting memories may consist only of the answers themselves, and not the processing that generated them.
Wong, K. W., & Scholl, B. J. (2023). Spatial affordances can automatically trigger dynamic visual routines: Spontaneous path tracing in task-irrelevant mazes. Talk presented at the annual meeting of the Vision Sciences Society, 5/14/23, St. Pete Beach, FL.
[Show abstract]
Visual processing usually seems both incidental and instantaneous. But imagine viewing a jumble of shoelaces, and wondering whether two particular tips are part of the same lace. You can answer this by looking, but doing so may require something dynamic happening in vision (as the lace is effectively 'traced'). Such tasks are thought to involve 'visual routines': dynamic visual procedures that efficiently compute various properties on demand, such as whether two points lie on the same curve. Past work has suggested that visual routines are invoked by observers' particular (conscious, voluntary) goals, but here we explore the possibility that some visual routines may also be automatically triggered by certain stimuli themselves. In short, we suggest that certain stimuli effectively afford the operation of particular visual routines (as in Gibsonian affordances). We explored this using stimuli that are familiar in everyday experience, yet relatively novel in human vision science: mazes. You might often solve mazes by drawing paths with a pencil -- but even without a pencil, you might find yourself tracing along various paths mentally. Observers had to compare the visual properties of two probes that were presented along the paths of a maze. Critically, the maze itself was entirely task-irrelevant, but we predicted that simply seeing the visual structure of a maze in the first place would afford automatic mental path tracing. Observers were indeed slower to compare probes that were further from each other along the paths, even when controlling for lower-level visual properties (such as the probes' brute linear separation, i.e. ignoring the maze 'walls'). This novel combination of two prominent themes from our field -- affordances and visual routines -- suggests that at least some visual routines may operate in an automatic (fast, incidental, and stimulus-driven) fashion, as a part of basic visual processing itself.